 |
www.chms.ru - вывоз мусора в Балашихе |
|
www.chms.ru - вывоз мусора в Балашихе |
Динамо-машины Сигналы и спектры
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 [ 163 ] 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358
на 1/3. Ограничений на количество соединяемых кодеров нет. Составные коды должны иметь одинаковую длину кодового ограничения и степень кодирования. Целью разработки турбокода является наилучший подбор составных кодов путем минимизации просвета кода [21]. При больших значениях EJNq это эквивалентно максимизации минимального весового коэффициента кодовых слов. Хотя при низких значениях EJNq (область, представляющая наибольший интерес) оптимизация распределения весовых коэффициентов кодовых слов является более важной, чем их максимизация или минимизация [20].
Рида-Соломона 01
Рида-Соломона 02
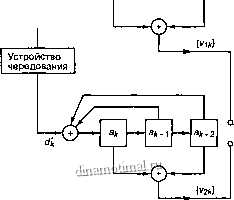
Рис. 8.26. Схема параллельного соединения двух RSC-кодерое
Турбокодер, изображенный на рис. 8.26, вьщает кодовые слова из каждого из двух своих составных кодеров. Распределение весовых коэффициентов кодовых слов без такого параллельного соединения зависит от того, сколько кодовых слов из одного составного кодера комбинируется с кодовыми словами из другого составного кодера.
Интуитивно понятно, что следует избегать спаривания кодовых слов с малым весовым коэффициентом из одного кодера с кодовыми словами с малым весовым коэффициентом из другого кодера. Большого количества таких спариваний можно избежать, сконфигурировав надлежащим образом устройство чередования. Устройство, которое обрабатывает данные случайным образом, более эффективно, чем рассмотренное ранее блочное устройство чередования [22].
Если составной кодер не рекурсивный, входная последовательность с единичным весовым коэффициентом (О О ... О О 1 О О ... О 0) всегда будет генерировать кодовое слово с малым весовым коэффициентом на входе второго кодера, при любой конструкции устройства чередования. Иначе говоря, устройство чередования не сможет повлиять на выходное распределение весовых коэффициентов кодовых слов, если составные коды не рекурсивные. Впрочем, если составные коды рекурсивные, входная последовательность с единичным весовым коэффициентом генерирует бесконечную импульсную характеристику (выход с бесконечным весовым коэффициентом). Следовательно, при рекурсивных кодах входная последовательность с единичным весовым
коэффициентом не дает кодового слова с минимальным весовым коэффициентом вне кодера. Кодированный выходной весовой коэффициент сохраняется конечным только при погашении решётки, процессе, принуждающем кодированную последовательность к переходу в конечное состояние таким образом, что кодер возвращается к нулевому состоянию. Фактически сверточный код преобразуется в блочный.
Для кодера, изображенного на рис. 8.26, кодовое слово с минимальным весовым коэффициентом для каждого составного кодера порождается входной последовательностью с весовым коэффициентом 3 (О О ... О О 1 1 1 О О О ... О 0) и тремя последовательными единицами. Другая последовательность, порождающая кодовые слова с малым весом, представлена последовательностью с весом 2 (О О ... О О 1 О О 1 О О ... О 0). Однако после перестановок, внесенных устройством чередования, любая из этих опасных структур имеет слабую вероятность появления на входе второго кодера, что делает маловероятной возможность комбинирования одного кодового слова с малым весом с другим кодовым словом с малым весом.
Важным аспектом компоновки турбокодов является их рекурсивность (систематический аспект незначителен). Это бесконечная импульсная характеристика, присущая кодам RSC, которая является защитой от генерации кодовых слов с малым весом, не поддающихся исправлению в устройстве чередования. Можно обсудить то, что производительность турбокодера сильно поддается влиянию со стороны кодовых слов с малым весом, производимых входной последовательностью с весом 2. В защиту этого можно сказать, что входную последовательность с весом 1 можно проигнорировать, поскольку она дает кодовые слова с большим весом из-за бесконечной импульсной характеристики кодера. Для входной последовательности, имеющей вес 3 и более, правильно сконфигурированное устройство чередования делает вероятность появления кодовых слов с малым весом на выходе относительно низкой [21-25].
8.4.5. Декодер с обратной связью
Использование алгоритма Витерби является оптимальным методом декодирования для минимизации вероятности появления ошибочной последовательности. К сожалению, этот алгоритм (с жесткой схемой на выходе) не подходит для генерации апостериорной вероятности (а posteriori probability - АРР) или мягкой схемы на выходе для каждого декодированного бита. Подходящий для этой задачи алгоритм был предложен Балом и др. [26]. Алгоритм Бала бьш модифицирован Берру и др. [17] для использования в кодах RSC. Апостериорную вероятность того, что декодированный бит данных
4 = /, можно вывести из совместной вероятности Л,/ , определяемой как
Л. = P{dt = raquo;, St = m\Ri ], (8.108)
где St = m - состояние кодера в момент времени к, а - принятая двоичная последовательность за время от fc = 1 в течение некоторого времени N.
Таком образом, апостериорная вероятность того, что декодированный информационный бит dt = i представляется как двоичная цифра, получается путем суммирования
совокупных вероятностей по всем состояниям.
P{dt=i\Ri} = Y,t =01 (8.109)
Далее логарифмическое отношение функций правдоподобия (log-likelihood ratio - LLR) переписывается как логарифм отношения апостериорных вероятностей.
(8.110)
Декодер осуществляет схему решений, известную как решающее правило максимума апостериорной вероятности (maximum а posteriori - MAP), путем сравнения
L(dt) с нулевым пороговым значением.
dj=l, если Udj) gt;0 g
dt = О, если L(dt) lt; О
Для систематического кода LLR L(dt), связанное с каждым декодированным битом dt, можно описать как сумму LLR для dt вне демодулятора и других LLR, порождаемых декодером (внешние сведения), как показано уравнениями (8.72) и (8.73). Рассмотрим детектирование последовательности данных с помехами, исходящей из кодера, изображенного на рис. 8.26, с помощью декодера, представленного на рис. 8.27. Предполагается, что используется двоичная модуляция и дискретный гауссов канал без памяти. Вход декодера формируется набором Rt из двух случайных переменных xt и yt. Для битов dt и Vi, которые в момент времени к представляются двоичными числами (1, 0), переход к принятым биполярным импульсам (+1, -1) можно записать следующим образом:
xt = {2dt-l) + it (8.112)
yt=(2yt-l) + qk- (8.113)
Здесь it и qt являются двумя случайными статистически независимыми переменными с одинаковой дисперсией Стг, определяющей распределение помех. Избыточная информация yt разуплотняется и пересылается на декодер DEC1 как у и, если vt = v,i, и на декодер DEC2 как уи, если vj = V2t. Если избыточная информация начальным декодером не передается, то вход соответствующего декодера устанавливается на нуль. Следует отметить, что выход декодера DEC1 имеет структуру чередования, аналогичную структуре, использованной в передатчике между двумя составными кодерами. Это связано с тем, что информация, обрабатываемая декодером DEC1, является неизмененным выходом кодера С1 (искаженной канальным шумом). И наоборот, информация, обрабатываемая декодером DEC2, является искаженным выходом кодера С2, вход которого составляют как раз те данные, что поступают в С1, но обработаны устройством чередования. Декодер DEC2 пользуется выходом декодера DEC1, обеспечивая такое же временное упорядочение этого выхода, как и входа С2 (т.е. две последовательности в декодере DEC2 должны придерживаться позиционной структуры сигналов в каждой последовательности).




